Retrieval-Augmented Generation (RAG) is one of those patterns that becomes more interesting the deeper you go.
Once you begin working with real workloads, two challenges show up quickly:
- Embedding API calls become expensive
- Cloud latency can be unpredictable
I wanted to experiment with a setup that balances cloud power with local flexibility—a system that feels good to develop with and doesn’t punish you for iterating.
This led to a small project I’ve been improving over time:
👉 containerized-Local-LLM-ingest-retrieve
https://github.com/premsgdev/rag-structure
The idea behind it is simple:
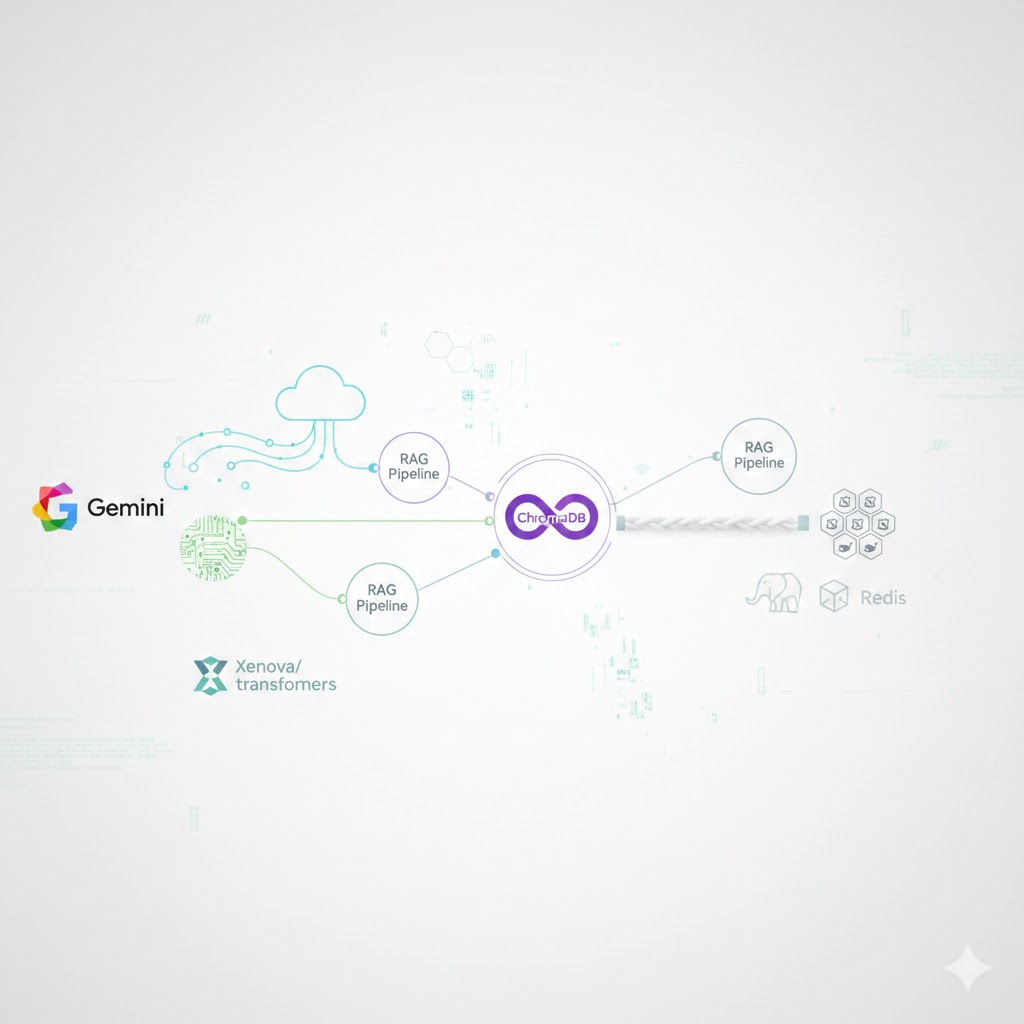
Let cloud models and local models work together inside the same RAG engine.
🔍 Why a Hybrid RAG Engine?
Traditional RAG systems rely entirely on cloud embeddings:
text → cloud embedding → vector DB → cloud LLM
It works, but it comes with a cost—literally.
So this project splits the embedding stage into two independent pipelines:
1️⃣ Cloud Embedding Path
- Model:
models/embedding-001(Gemini) - Stored in: ChromaDB collection
policies - Strengths: high-quality semantic embeddings, predictable behavior
2️⃣ Local Embedding Path
- Model:
all-MiniLM-L6-v2(Xenova / transformers) - Stored in: ChromaDB collection
policies_xenova - Strengths: zero cost, fast, ideal for local development and fallback
Both embedding paths write to the same ChromaDB instance running locally, but they use different collections to keep vector spaces completely isolated.
The final LLM answer still comes from Gemini, but the pipeline becomes flexible and cost-aware.

This captures the flow:
- Documents → two embedding pipelines
- Both pipelines write to separate collections in the same local ChromaDB instance
- Retrieval chooses the appropriate collection
- Gemini generates the final answer
⚙️ Cloud Ingestion: Batching Embeddings
The cloud pipeline uses Gemini’s embedding model. Batching is essential to stay efficient:
| |
Why batching matters:
- Reduces API calls
- Avoids hitting rate limits
- Improves ingestion throughput
- All cloud embeddings are saved into the policies collection inside ChromaDB.
⚡ Local Ingestion: Fast and Free
Local embeddings run entirely inside Node.js using Xenova/transformers
| |
Two important parameters:
- pooling: "mean" — produces one vector per chunk
- normalize: true — required for consistent cosine similarity searches
These embeddings go into the policies_xenova collection in the same local ChromaDB instance.
🏗️ Containerized Infrastructure
Everything is built to be reproducible and easy to spin up. The entire system runs using Docker Compose:
ChromaDB (vector store)
- Runs locally inside Docker
- Holds two collections, one for cloud embeddings, one for local embeddings
- Same instance, logically separated vector spaces
PostgreSQL
- Stores metadata like document source, timestamps, and types
- Enables hybrid search: semantic (Chroma) + structured filters
Redis
- Caches frequent LLM responses
- Reduces repeated calls to Gemini
Node.js services
- Cloud ingestion
- Local ingestion
- Retrieval
- Helpers for embedding and vector operations
🔁 Retrieval Flow

🌱 Why I Built This
I enjoy exploring the space where developer experience, performance, and cost meet. RAG is powerful, but I’ve always felt it could be made more flexible—something you can run anywhere, tweak freely, and experiment with safely.
This hybrid setup grew out of that curiosity.
If you’re working on retrieval systems yourself, I hope this gives you a useful starting point or sparks a new idea.
🔗 Repository
👉 containerized-Local-LLM-ingest-retrieve https://github.com/premsgdev/rag-structure
If this helps you build your own RAG pipeline—or inspires improvements—I’d love to see what you create.
Happy building! 🚀